Linux 常见系统进程及参数说明
Memory
内存管理相关的系统关键进程
| Name | Path | Info | Demonstrate |
|---|---|---|---|
[kswapd0] |
由内核启动 | Linux 内核中的一个内存管理守护进程,负责内存交换(swap).当系统内存不足时,触发内存回收机制,释放不常用的内存页。内存回收使用 Page Replacement 算法(新版本使用) |
kswapd |
内存管理相关的系统关键进程
| Name | Path | Info | Demonstrate |
|---|---|---|---|
[kswapd0] |
由内核启动 | Linux 内核中的一个内存管理守护进程,负责内存交换(swap).当系统内存不足时,触发内存回收机制,释放不常用的内存页。内存回收使用 Page Replacement 算法(新版本使用) |
kswapd |
使用 lsmod 命令列出所有已加载的内核模块,输出中包含: 模块名称(Name)、大小(Size) 和 何处被使用(Used by)
lsmod |
要查看已加载的内核模块的详细信息,可以使用 modinfo 命令,不是所有的模块都有详细的描述信息,如果没有,则无任何返回
modinfo -d ena |
modinfo 命令常用选项:
| 选项 | 说明 | 示例 |
|---|---|---|
-a, --author |
打印模块的作者 | |
-d, --description |
打印模块的描述信息 | |
-p, --parameters |
打印模块的 ‘parm’ | |
-n, --filename |
Print only ‘filename’ |
使用 insmod 命令加载内核模块. 模块需要完整后缀(如果有)
insmod simple.ko |
使用 modprobe 命令加载内核模块. 模块不需要完整后缀(如果有) 。临时加载,重启后会消失。
modprobe parport |
使用 rmmod 命令卸载内核模块。无需后缀,只需要给定模块名
rmmod simple |
也可以使用命令 modprobe -r 移除模块,它不仅会移除指定的模块,还会移除未被继续使用的依赖的模块
| 文件路径 | 说明 | 示例 |
|---|---|---|
| /etc/motd | 登录成功后的欢迎信息,ssh 登录和 console 登录成功后都会显示 | |
| /etc/issue | 在登录系统输入用户名之前显示的信息,远程 ssh 连接的时候并不会显示此信息 | 说明示例 |
| /etc/services | 记录网络服务名和它们对应使用的端口号及协议 | |
| /etc/protocols | 该文件是网络协议定义文件,里面记录了 TCP/IP 协议族的所有协议类型。文件中的每一行对应一个协议类型,它有3个字段,分别表示 协议名称、协议号 和 协议别名 |
|
| /etc/vimrc ~/.vimrc |
vim 启动时会读取 /etc/vimrc(全局配置) 和 ~/.vimrc (用户配置) |
vim |
| /etc/passwd /etc/shadow /etc/group |
用户数据库,其中记录了 用户名,id,用户家目录,shell 等用户密码文件 组信息 |
|
| /etc/fstab | 系统启动时需要自动挂载的文件系统列表 | |
| /etc/mtab | 当前系统已挂载的文件系统,并由 mount 命令自动更新。当需要当前挂载的文件系统的列表时使用(例如df命令) |
|
| /etc/shells | 系统可使用的 shell |
|
| /etc/filesystems | 系统可使用的 文件系统 |
|
| /etc/hostname | 存放这主机名 | |
| /etc/hosts | 主机名查询静态表,域名和 ip 本地静态表 | |
| /etc/nsswitch.conf | 它规定通过哪些途径以及按照什么顺序以及通过这些途径来查找特定类型的信息,还可以指定某个方法奏效或失效时系统将采取什么动作 | hosts: files dns myhostname此配置设定:在查找域名解析的时候,先查找本地 /etc/hosts,再发送给 DNS 服务器查询 |
| /etc/rsyslog.conf | rsyslog 服务的配置文件,用来托管其他服务的日志 |
linux rsyslog 服务 |
| /etc/logrotate.conf | linux 日志切割工具 | linux logrotate 服务 |
| /etc/rsyncd.conf | rsync 服务的配置文件 |
rsyncd 服务 |
| /etc/sysctl.conf /etc/sysctl.d/ |
内核的运行参数配置文件,sysctl 命令对内核参数的修改仅在当前生效,重启系统后参数丢失,如果希望参数永久生效可以修改此配置文件 |
Linux 常用内核参数说明 |
在 Python 中,set 是一种无序的、可变的集合数据类型,用于存储唯一的元素。它主要用于快速去重和集合运算(如交集、并集、差集等)。
可以使用花括号 {} 或 set() 函数来创建集合。
使用花括号创建集合
# 创建一个包含一些元素的集合 |
使用 set() 函数创建集合
# 使用 set() 函数从一个可迭代对象创建集合 |
使用 add() 方法向集合添加单个元素。
my_set = {1, 2, 3} |
使用 remove() 方法移除集合中的指定元素,如果元素不存在会引发 KeyError。使用 discard() 方法移除元素,如果元素不存在不会引发异常。
my_set = {1, 2, 3} |
使用 clear() 方法清空集合中的所有元素。
my_set = {1, 2, 3} |
使用 len() 函数获取集合中元素的个数。
my_set = {1, 2, 3} |
使用 | 运算符或 union() 方法。
set1 = {1, 2, 3} |
str1 = 666 |
|
str1 = 666 |
yield 指令和 return 相似,都是用来在函数中返回。使用 yield 关键字创建生成器函数时,生成器函数并不会在传统意义上 返回。相反,生成器函数在遇到 yield 语句时会暂停其执行,并返回一个值给调用者。生成器函数的状态会被保存,因此在下一次调用时,它可以从暂停的地方继续执行。
yield 指令 将函数转换成生成器(Generator),它在函数中产生一个值,然后暂停函数并保存其状态(下一次调用函数会从此状态恢复执行),再次恢复执行时再生成(返回)yield 的值。
每次调用生成器函数时,并不会立即执行,会创建一个新的生成器对象。
第一次使用 next() 或在 for 循环中开始迭代生成器时,生成器函数开始执行,直到遇到第一个 yield 语句。yield 会暂停生成器函数的执行,并将一个值返回给调用者。再次调用 next() 或继续迭代(for)时,生成器函数从上次暂停的 yield 处继续执行,直到遇到下一个 yield 语句或执行结束。
生成器函数在没有 yield 语句时结束执行,相当于隐式地在最后一个 yield 语句之后遇到 return。
当生成器函数结束时,进一步调用 next() 会引发 StopIteration 异常,表示生成器中的值已被全部生成。
yield 有以下优点:
yield)不会继续执行,直到再次调用 next() 或通过迭代器进行迭代(for)。在处理大文本数据(如超过 10G)时,如果一次性读取所有文本内容,在可用内存较小的情况下可能出现内存不足导致程序执行失败。这时候可以考虑使用 yield 来批量加载数据。
定义如下函数读取文件内容:
def read_large_file(file_path): |
使用以下方法使用大文本中的数据
next 方法。调用生成器函数(read_large_file),会返回一个 Generator 对象,通过 next() 方法会迭代调用生成器的下一个值(yield 表达式的值) file_path = 'large_file.txt' |
for 循环。调用生成器函数返回一个生成器对象,这个对象实现了迭代器协议。 def read_large_file(file_path): |
在处理大文件的过程中,如果需要批量多行读取文件内容,参考以下代码
def read_file_in_chunks(file_path, chunk_size=1024): |
enumerate 是 Python 内置函数之一,用于遍历可迭代对象(如列表、元组或字符串)时获取元素和对应的索引。
语法:
enumerate(iterable, start=0) |
iterable : 任何可迭代对象(如列表、字符串、元组、文件对象等)。start : 索引的起始值,默认为 0。如果要让索引号从 1 开始,配置 start=1示例列表 |
使用 eval 将 string 转化成 dict 时出错,经过排查,发现 string 数据中包含 null,在转换时就会报错: NameError: name ‘null‘ is not defined
解决方法
使用 json 进行转换
try: |
蛙化及蛇化
蛙化現象 是日本 2023 年上半年的 Z 世代(出生介於1995年~2010年)流行用語第一名。這個詞源自格林童話《青蛙王子》,描述對另一半突然感到生理或心理上厭惡。
日本大學教授藤澤伸介在2004年的研究指出,「蛙化現象」是一種普遍狀態,尤其容易發生在情竇初開的青少年身上,因為戀愛經驗少,對感情對象抱持完美的想像。
與蛙化現象相對,近期有對情侶在TikTok發明「蛇化現象」,描述無論另一半做了什麼尷尬行為,都感到好可愛。這種現象迅速散播,成為日本Z世代流行用語。
于高山之巅,方见大河奔涌;于群峰之上,更觉长风浩荡
你永远不可能真正去了解一个人,除非你穿过她的鞋子去走她走过的路,站在她的角度思考问题,可当你走过她走的路时,你连路过都觉得难过。
当一个人因为和你无关的事情而生气并向你抱怨和展示自己的生气和愤怒时,你最好不要对涉及到的人或事发表任何意见,千万不要对涉及到的人或事发表任何意见,千万不要对涉及到的人或事发表任何意见,你最好 当个听客,闭紧嘴巴,不然很可能引火烧身。
当你只能孤注一掷的时候,你只能孤注一掷。如果你犹豫不决,说明你其实还有办法,只是不愿意使用。
对一个人好是一件太过笼统的说法,没法测量,如需测量,可以将这个说法进行分解,比如分解为:
对一个人好 = 能为他着想 + 站在他的角度考虑
| 状态标识 | 状态名称 | 状态说明 | 示例 |
|---|---|---|---|
R |
task_running | 进程处于运行或就绪状态 | |
S |
task_interruptible sleeping |
可中断的睡眠状态 | |
D |
task_uninterruptible | 不可中断的睡眠状态 1. 它是一种睡眠状态,意味着处于此状态的进程不会消耗 CPU 2. 睡眠的原因是等待某些资源(比如锁或者磁盘 IO),这也是非常多 D 状态的进程都处在处理 IO 操作的原因 3. 是它不能被中断,这个要区别于 硬件中断 的中断,是指不希望在其获取到资源或者超时前被终止。因此他不会被信号唤醒,也就不会响应 kill -9 这类信号。这也是它跟 S(可中断睡眠)状态的区别 |
|
T |
task_stopped task_traced Traced |
暂停状态或跟踪状态 | |
Z |
task_dead exit_zombie zombie |
退出状态,进程成为僵尸进程 | |
X |
task_dead exit_dead |
退出状态,进程即将被销毁 | |
I |
idle | 空闲状态 |
在系统中遇到以下进程:
ps -elf | grep 18686 |
其中 PID 为 18686 的进程名为 /usr/sbin/CROND,其启动了另外两个子进程。但是在系统中检查,并不存在路径 /usr/sbin/CROND
ls -l /usr/sbin/CROND |
出现此种现象,主要是因为 在启动时,进程的命令名是根据路径传递给 execve() 函数的参数决定的,而不是直接与系统中的文件进行匹配。
在 Linux 系统中,ps 命令显示的进程信息是从 /proc 文件系统中获取的,而 /proc 文件系统包含有关正在运行的进程的信息,包括每个进程的命令名。因此,即使实际上系统中不存在 /usr/sbin/CROND 文件,但如果进程的命令名是 /usr/sbin/CROND,那么 ps 命令仍然会显示进程的命令名为 /usr/sbin/CROND。
进程的命令名可以查看 /proc/<PID>/cmdline 文件,本示例中显示如下:
cat /proc/18686/cmdline |
对应的系统上的可执行文件的名称可以查看 /proc/<PID>/stat、/proc/<PID>/comm、/proc/<PID>/status 等文件
cat /proc/900/comm |
在本示例中,实际执行的命令为 crond
使用 top 命令可以查看系统负载、CPU 和 内存使用情况。也可以查看单个进程的具体信息。
top 命令常用选项
| 选项 | 说明 | 示例 |
|---|---|---|
-H |
Threads Mode,线程模式。默认情况 top 展示进程的简要信息,使用此选项显示进程中的线程状态。对应交互式命令 H |
top -H -p 1423 |
Ansible 使用 Jinja2 模板语言对变量或者 Facts 进行模板化。 [1]
使用 Filters 可以进行数据转换(如 JSON –> YAML)、URL 分割等操作。 [2]
在模板中使用的变量未定义的情况下,可能会导致 Ansible 处理失败,为了以更优雅的方式处理此类问题,可以在模板中为变量提供 默认值
{{ some_variable | default(5) }} |
也可以在变量计算值为空或者 false 时使用默认值
{{ lookup('env', 'MY_USER') | default('admin', true) }} |
默认情况下,Ansible Template 中所有的变量都必须有值,否则会抛出异常。假如需要在模板中的部分变量没有值或未定义的情况下也可以正常部署,可以将其配置为 可选(optional)
要将变量配置为 **可选(optional)**,可以将其 默认值(default value) 设置为特殊变量 omit
- name: Touch files with an optional mode |
如果需要对变量类型进行转换,可以参考以下方法
2.3 以上版本中,可以使用 type_debug 显示变量类型
{{ myvar | type_debug }} |
New in version 2.6.
{{ dict | dict2items }} |
原始字典数据:
tags: |
使用 {{ dict | dict2items }} 转换后的列表数据:
- key: Application |
转换后的列表默认以关键字 key 指示之前的字典中的 key 值,以关键字 value 指示之前的字典中的 value 值。如果想要自定义 key 名称,dict2items 接受关键字参数 key_name 和 value_name
Dictionary data (before applying the ansible.builtin.dict2items filter): |
{{ tags | items2dict }} |
List data (before applying the ansible.builtin.items2dict filter):
tags: |
Dictionary data (after applying the ansible.builtin.items2dict filter):
Application: payment |
假如 List Data 中的关键字不是 key 和 value,此时必须使用参数 key_name 和 value_name 指定
{{ fruits | items2dict(key_name='fruit', value_name='color') }} |
使用以下语法强制转换变量数据类型 [5]
some_string_value | bool |
可以使用以下语法将数据转换为 JSON 或者 YAML 格式
{{ some_variable | to_json }} |
可以使用以下语法将数据转换为方便人类阅读 JSON 或者 YAML 格式
{{ some_variable | to_nice_json }} |
制定行首缩进程度
{{ some_variable | to_nice_json(indent=2) }} |
Compose 项目是 Docker 官方的开源项目,负责实现对 Docker 容器集群 的快速编排。
Compose 定位是 「定义和运行多个 Docker 容器的应用(Defining and running multi-container Docker applications)」,其前身是开源项目 Fig。
使用一个 Dockerfile 模板文件,可以让用户很方便的定义一个单独的应用容器。然而,在日常工作中,经常会碰到需要多个容器相互配合来完成某项任务的情况。例如要实现一个 Web 项目,除了 Web 服务容器本身,往往还需要再加上后端的数据库服务容器,甚至还包括负载均衡容器等。
Compose 恰好满足了这样的需求。它允许用户通过一个单独的 docker-compose.yml 模板文件(YAML 格式)来定义一组相关联的应用容器为一个项目(project)。Compose 中有两个重要的概念:
服务 (service) : 一个应用的容器,实际上可以包括若干运行相同镜像的容器实例。 项目 (project) : 由一组关联的应用容器组成的一个完整业务单元,在 docker-compose.yml 文件中定义。Compose 的默认管理对象是项目,通过子命令对项目中的一组容器进行便捷地生命周期管理。
Compose 目前分为 2 个大版本: [1]
Compose V1 : 目前已经不提供官方支持。使用 Python 编写,通过 docker-compose 命令来调用。Compose V1 的 docker-compose.yml 最开始要包含 version 命令,取值范围 2.0 到 3.8Compose V2 : 使用 Go 编写,通过 docker compose 命令来调用。Compose V2 忽略 docker-compose.yml 最开始的 version 指令。Compose V2 向后兼容 Compose V1 版本YAML(YAML Ain’t Markup Language)是一种专门用于数据序列化的格式,常用于配置文件、数据交换等场景。它以其可读性和简洁性而受到开发者的青睐。YAML设计的目标是易于人类阅读和编写,并且易于与其他编程语言进行交互。下面是YAML语法的详细介绍
数据类型 :YAML 支持标量(如字符串、整数、浮点数)、序列(列表)和映射(字典)三种基本数据类型。
缩进 :YAML 使用缩进表示结构层级关系,通常每个层级缩进两个或四个空格(禁止使用制表符)。
标量(Scalars) 是单个的、不可分割的值。可以是字符串、整数或浮点数。标量可以是单行的值,也可以是多行的值
单行字符串 |
多行字符串可以使用字面量样式(|)或折叠样式(>):
字面量样式保留换行符 |
true, false, null 等特定词汇表示布尔值和 Null。列表(Sequences) 是一组按顺序排列的值(类似于数组或列表),用破折号加空格表示新的元素,每个列表项占一行,也需要正确缩进。
列表 |
映射/字典(Mappings) 是键值对的集合(类似于字典或哈希表),用冒号加空格表示键值对,键值对需要正确缩进
字典 |
列表和字典可以嵌套使用,形成复杂的结构
嵌套的列表和字典 |
YAML支持定义锚点(&)和别名(*)来重用(引用)文档中的某部分,使用 & 创建一个锚点(alias),之后可以用 * 引用这个锚点。
使用 << 和 * 来合并已有(引用)的映射。
使用锚点和别名 |
使用井号 # 开始一个注释,井号后面的内容将被视为注释,注释内容直到行尾。
一个 YAML 文件可以包含多个文档,每个文档用三个短横线 --- 分隔。
--- |
为 process-exporter 生成 systemd 服务启动配置文件:
[Unit] |
建议将 process-exporter 的配置写入文件并使用 -config.path 指定配置文件。
process-exporter 在配置文件中使用模板变量来配置筛选要监控的进程,可以使用的模板变量包括:
| 变量 | 说明 | 示例 |
|---|---|---|
{{.Comm}} |
匹配进程的命令名(不包括路径)。主要来源于 /proc/<pid>/stat 输出中的第二部分命令名是指进程执行时的名称。在 Linux 系统中,可以通过 /proc/<PID>/comm 文件来获取进程的命令名。例如,如果一个进程执行的命令是 /usr/local/bin/php,那么它的命令名就是 php。 |
|
{{.ExeBase}} |
匹配进程的可执行文件名,不包括路径 可执行文件名是指进程的完整路径的最后一个部分。例如,如果一个进程的完整路径是 /usr/local/bin/php,那么它的可执行文件名就是 php。 |
|
{{.ExeFull}} |
匹配进程的可执行文件的完整路径,例如 /usr/local/php73/bin/php |
|
{{.Username}} |
匹配进程的用户名 | |
{{.Matches}} |
匹配进程的命令行参数列表 | |
{{.StartTime}} |
||
{{.Cgroups}} |
要监控系统上的所有进程的运行情况,可以参考以下配置: [1]
process_names: |
- 以上配置会获取到系统上的所有进程(子进程被统计入父进程中)
- 假如配置中有多个匹配项,以上配置不能放到第一个,否则因为其可以匹配到系统中所有的进程,后续配置的匹配不会再有机会生效
假如系统中运行了多个 php 的子进程,为了获取到各个子进程的统计数据,可以参考以下配置
process_names: |
使用此配置,可以获取到系统中以下进程的统计数据:
/usr/local/php73/bin/php /home/www/admin/artisan Pulldata/usr/local/php73/bin/php /home/www/admin/artisan schedule:run/usr/local/php73/bin/php /home/www/admin/artisan queue:work除可以获取到以上特定进程的统计数据外,还可以统计到除此之外的其他所有进程的统计数据。
因为配置中匹配进程的顺序的关系,假如系统中还有除此之外的其他
php进程,那么由最后的{{.Comm}}统计到的php进程资源使用数据中不再包含前面 3 个特定进程的资源使用数据。
Nextcloud All-in-One 在一个 Docker 容器中提供了方便部署和维护的 Nextcloud 方式。[1]
为方便后期管理及迁移,建议使用 docker compose 方式部署。docker-compose.yml 参考文件如下: [2]
version: "3" |
使用 docker compose 方式部署注意事项:
name: nextcloud_aio_mastercontainer: Volume 名称必须是 nextcloud_aio_mastercontainer,否则会报错找不到卷 nextcloud_aio_mastercontainer: It seems like you did not give the mastercontainer volume the correct name? (The 'nextcloud_aio_mastercontainer' volume was not found.). Using a different name is not supported since the built-in backup solution will not work in that case!启动成功后,根据提示在浏览器中打开 Nextcloud AIO setup 页面并记录页面显示的密码
You should be able to open the Nextcloud AIO Interface now on port 8080 of this server! |
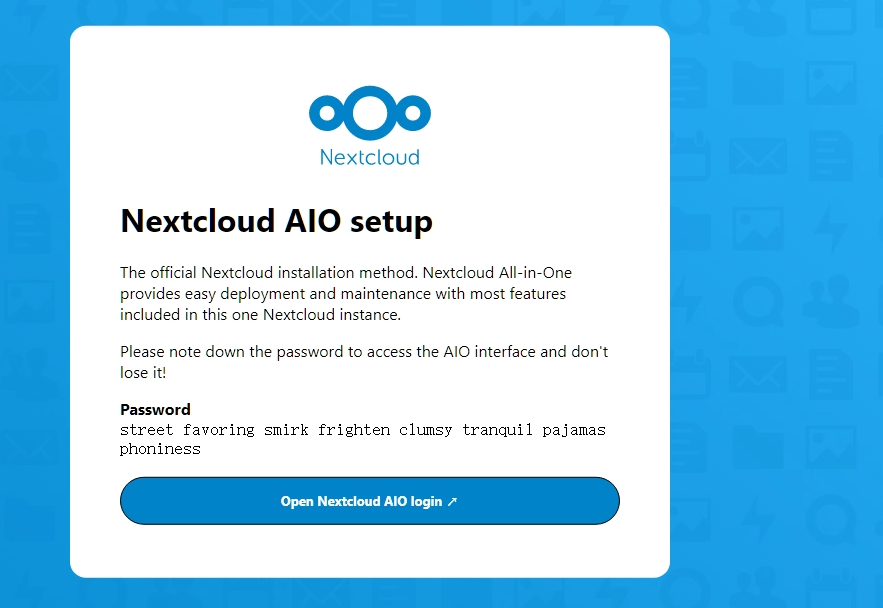
根据页面提示登陆,跟随页面提示进行新实例初始化。
初始化过程中要提供域名,系统会自动为域名颁发证书(使用系统 443 端口映射到容器中的 8443 端口)
默认的 Nextcloud AIO 未部署反向代理,要使用反向代理请参考文档: Reverse Proxy Documentation
Prometheus ValKey & Redis Metrics Exporter
Prometheus Redis Metrics Exporter 下载页面
wget https://github.com/oliver006/redis_exporter/releases/download/v1.59.0/redis_exporter-v1.59.0.linux-amd64.tar.gz |
为 redis_exporter 生成 systemd 服务配置文件 /usr/lib/systemd/system/redis_exporter.service
[Unit] |
启动 redis_exporter 服务
systemctl daemon-reload |
redis_exporter 服务启动后,默认启动 9121 端口提供 Metrics 数据供 Prometheus 抓取。
如果要通过一个 redis_exporter 实例监控多个 Redis 实例,可以参照以下配置文件配置 Redis 实例及其认证信息,如果无需密码认证,则保留密码项为空。
|
修改 redis_exporter 启动参数,使其读取上面配置的实例和其认证信息
/usr/bin/redis_exporter -redis.password-file /etc/redis_exporter_pwd_file.json |
参考以下配置使用文件发现的方式配置被监控的 Redis 实例
|
targets-redis-instances.yml 文件内容包含 Targets 内容:
- labels: |
首先在 telegram 中搜索 @BotFather,和其对话,根据提示创建 机器人,记录下生成的 token 信息
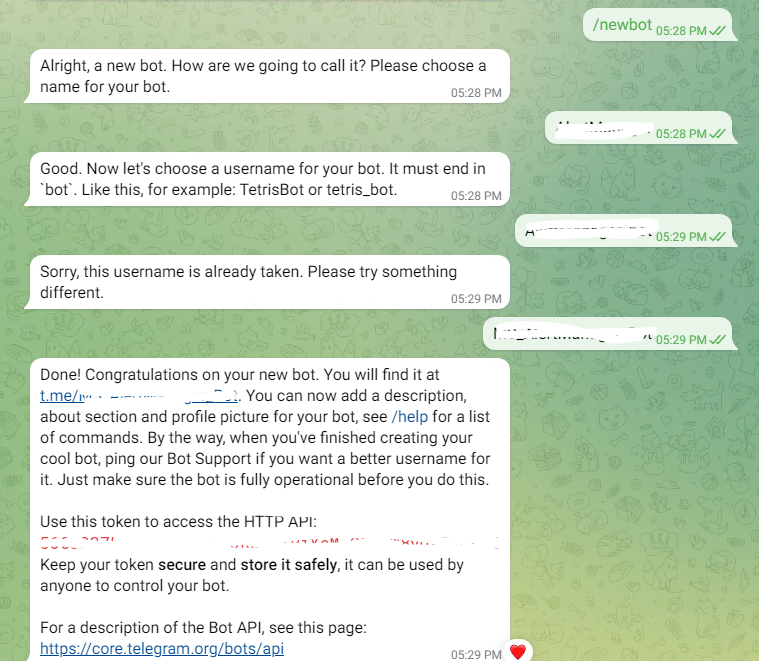
创建新的 Channel 或者 Group 或者将刚刚新建的 Bot 加入已有的 Channel/Group。
获取 ChatGroup ID,可以使用以下方法之一
添加机器人 @getmyid_bot 到 Channel,会自动显示 Chat ID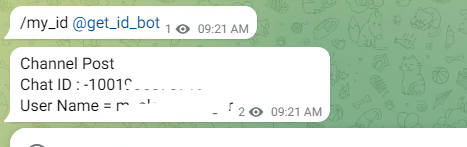
使用以下代码获取
>> import requests |
curl -v "https://api.telegram.org/bot{token}/sendMessage?text=sa&chat_id=-992754669" |
>> import requests |
需要安装 python-telegram-bot
pip install --upgrade python-telegram-bot |
发送消息代码
>> import telegram |
如果需要在非异步环境中(例如 Django 试图函数) 运行以上异步代码,会报错: RuntimeError: There is no current event loop in thread 'Thread-1'。需要特殊处理,可以使用 asyncio.run() 函数来运行异步代码,它可以在非异步环境中创建一个新的事件循环并运行异步函数。
Django 视图中参考代码如下
def send_message_to_tg(chat_id: int, text: str): |
本文档主要做为需要安装或升级 Nginx 版本或者需要重新编译 Nginx 为其添加新模块时的参考。Nginx 服务常用配置说明
编译安装 Nginx 之前,首先需要安装依赖包 [1]
cd /tmp |
cd /tmp |
cd /tmp |
下载 Nginx stable 版本编译安装
wget https://nginx.org/download/nginx-1.24.0.tar.gz |
要启用或者停用指定的 Nginx 自带模块,参考 Nginx 编译配置选项说明
此处编译配置添加第三方模块 nginx-module-vts 以支持 Prometheus。执行以下命令编译 Nginx 并添加第三方模块 nginx-module-vts。Nginx 和 nginx-module-vts 版本兼容列表
wget https://github.com/vozlt/nginx-module-vts/archive/refs/tags/v0.2.2.tar.gz |
编译安装后的软件包,只需要安装好依赖,便可以迁移到其他机器上面使用,本文档编译安装后的软件包下载链接
为了能使用 systemctl 管理源码编译安装的 nginx,可以为其使用以下配置文件将其托管到 systemd
[Unit] |
参考步骤安装 nginx-module-vts 模块,以支持 Prometheus 采集 Nginx 统计数据。
如果要统计 Nginx 所有的 vhost 数据,则将 nginx-module-vts 模块相关配置放置于 http 模块内,否则可以在只想要监控(统计)的 vhost (server 配置段) 中添加配置。
nginx-module-vts 模块相关配置命令说明:
| 命令 | 说明 | 用法示例 |
|---|---|---|
vhost_traffic_status_zone |
定义 vhost_traffic_status 模块使用的共享内存区域。用于存储虚拟主机的流量统计信息 |
vhost_traffic_status_zone shared_memory_name size;shared_memory_name 是共享内存区域的名称,size 是共享内存区域的大小。 |
vhost_traffic_status_filter_by_host |
按主机名过滤虚拟主机状态信息 默认会将流量全部计算到第一个 server_name 上;启用后,只会显示与请求的主机名匹配的虚拟主机状态信息。 |
vhost_traffic_status_filter_by_host on; |
vhost_traffic_status_filter_by_set_key |
根据自定义键值对来过滤虚拟主机的状态信息 | vhost_traffic_status_filter_by_set_key $host$request_uri; |
vhost_traffic_status_filter_by_set_zone |
过滤器使用的共享内存区域 | |
vhost_traffic_status_display |
用于显示虚拟主机状态信息的格式 支持 json、CSV 和 html |
vhost_traffic_status_display_format html; |
vhost_traffic_status_display_format |
用于显示虚拟主机状态信息的字段格式。 可以选择显示的字段有:request、status、request_time、request_length、request_method、request_uri、request_length、request_time、request_time_counter、request_time_counter_overflows、request_time_min、request_time_max、request_time_avg、request_time_median、request_time_percentile。 |
vhost_traffic_status_display_format field1 field2 ...; |
为了获取所有域名的统计信息,在 Nginx 的 http 模块内添加以下配置:
http { |
重载配置后查看请求内容:
curl localhost:8888/status |
统计信息输出结果支持多种格式:
localhost:8888/status/format/json - Jsonlocalhost:8888/status/format/html - Htmllocalhost:8888/status/format/jsonp - Jsonplocalhost:8888/status/format/prometheus - Prometheuslocalhost:8888/status/format/control - control在 Prometheus 中添加以下 Targets 配置抓取 nginx-module-vts 模块暴露出的统计信息
- job_name: "Nginx" |
在 Prometheus 中检查抓取到的数据
Nginx 编译安装成功后,启动报错
/usr/local/nginx-1.24.0/sbin/nginx -t |
问题原因 为 Nginx 在系统的库文件路径中未找到已经安装的 libpcre2-8.so.0 库文件。可以通过以下方式验证
libpcre2-8.so.0,可以看到系统上已经存在此库文件 /usr/local/lib/libpcre2-8.so.0 find / -name libpcre2-8.so.0 |
/usr/local/lib/libpcre2-8.so.0 ldconfig -p | grep libpcre |
/etc/ld.so.conf,发现其中不包括路径 /usr/local/lib/,因此位于此路径下的共享库文件无法被搜索到 cat /etc/ld.so.conf |
要解决此问题,可以使用以下方法之一:
添加 /usr/local/lib/ 到系统共享库查找路径配置文件 /etc/ld.so.conf
include ld.so.conf.d/*.conf |
执行以下命令,使配置生效
ldconfig |
设置系统环境变量 LD_LIBRARY_PATH,这个变量定义了系统共享库的查找目录。将 /usr/local/lib 添加到此变量的值中,要永久生效需要将其写入配置文件,如 ~/.bash_profile 等
export LD_LIBRARY_PATH="/usr/local/lib:$LD_LIBRARY_PATH" |
创建符号链接
ln -s /usr/local/lib/libpcre2-8.so.0 /usr/local/nginx-1.24.0/sbin/libpcre2-8.so.0 |
或者
ln -s /usr/local/lib/libpcre2-8.so.0 /lib64/libpcre2-8.so.0 |
执行以下命令执行编译前配置时报错 ./configure: error: SSL modules require the OpenSSL library.:
./configure --prefix=/usr/local/nginx-1.24.0 \ |
此报错原因为未找到 OpenSSL 的库文件。
针对此场景,可以通过在编译配置时指定 OpenSSL 的源码中库文件的具体位置(--with-openssl=/tmp/openssl-1.1.1t),参考以下命令
./configure --prefix=/usr/local/nginx-1.24.0 \ |
Nginx 执行 make 命令时报错: /bin/sh: line 2: ./config: No such file or directory
./configure --prefix=/usr/local/nginx-1.24.0 \ |
错误信息表明在编译 nginx 时,make 命令无法找到 OpenSSL 的配置脚本 config。此脚本位于 OpenSSL 的源码目录中。可以通过 --with-openssl=/tmp/openssl-1.1.1t 指定。
修改编译前的配置命令如下:
./configure --prefix=/usr/local/nginx-1.24.0 \ |
nginx 报错
nginx: the configuration file /usr/local/nginx-1.24.0/conf/nginx.conf syntax is ok |
问题原因 为 nginx 用户不存在,创建 nginx 用户或者修改配置文件,使用已有的用户运行 nginx
配置 Prometheus 监控 Kubelet 之后可以采集到 Kubelet 监控指标。
配置 Prometheus 读取 cAdvisor 之后可以通过 cAdvisor 采集到容器相关的监控指标。
| 指标名称 | 类型 | 说明 | 示例 |
|---|---|---|---|
kubelet_pod_start_duration_seconds_count |
Pod 启动的时间 | ||
kubelet_pod_start_duration_seconds_bucket |
Pod 启动的时间的延迟直方图数据 | kubelet_pod_start_duration_seconds_bucket{le="0.5"} |
|
kubelet_running_pods |
运行的 Pod 的数量 | ||
kubelet_running_containers |
运行的 Containers 的数量 | ||
kubelet_runtime_operations_errors_total |
Kubelet 和 CRI 交互产生的错误(类型) | ||
kubelet_started_containers_total |
Kubelet 启动的 Container 总数 | ||
kubelet_started_pods_total |
Kubelet 启动的 Pod 总数 | ||
kubelet_volume_stats_available_bytes |
PV Volume 可以使用的磁盘空间 | ||
kube_node_status_allocatablekube_node_status_capacity |
节点的可分配的 资源 数量 | kube_node_status_allocatable{resource="pods"}节点可分配的 Pod 的数量 |
|
kubelet_started_pods_total |
Counter |
已启动的 Pod 数量 | |
container_cpu_usage_seconds_total |
Counter |
Container 使用的 CPU | |
container_memory_usage_bytes |
Gauge |
Pod 使用的内存 | container_memory_usage_bytes{namespace="default"} |
kube_pod_container_status_restarts_total |
Counter |
Pod 的重启次数 |
配置 Prometheus 监控 Ingress-Nginx-Controller 指标 后,Prometheus 可以读取到 Ingress-Nginx-Controller 暴露的监控指标。
Grafana 中配置使用 Ingress-Nginx-Controller 指标示例
| 指标名称 | 类型 | 说明 | 示例 |
|---|---|---|---|
nginx_ingress_controller_requests |
Counter |
Ingress Nginx Controller 接收到的所有请求数,,包括各个状态码 | irate(nginx_ingress_controller_requests[2m]) - 请求速率 |
nginx_ingress_controller_nginx_process_connections |
连接数,包括各个状态码 | ||
nginx_ingress_controller_request_duration_seconds_sum |
请求持续时间的总和 请求持续时间是从请求进入 Ingress 控制器开始,到响应返回给客户端结束的整个时间 |
||
nginx_ingress_controller_request_duration_seconds_count |
请求持续时间的计数。 | 计算平均请求持续时间:平均请求持续时间 = 请求持续时间总和 / 请求持续时间计数 | |
nginx_ingress_controller_ingress_upstream_latency_seconds_sum |
upstream 占用时间的总和 upstream 占用时间是指请求从 Ingress 到达 upstream(backend)服务器的时间 |
||
nginx_ingress_controller_ingress_upstream_latency_seconds_count |
upstream 上游占用时间的计数 | 计算平均上游占用时间:平均上游占用时间 = 上游占用时间总和 / 上游占用时间计数。 |
包括 CPU 架构、内核版本、操作系统类型、主机名等,集中在指标 node_uname_info 中。
| 指标名称 | 类型 | 说明 | 示例 |
|---|---|---|---|
node_cpu_seconds_total |
Counter |
CPU 使用时间 | node_cpu_seconds_total{mode="idle"} - CPU 空闲时间 |
100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) |
| 指标名称 | 类型 | 说明 | 示例 |
|---|---|---|---|
node_memory_MemTotal_bytes |
Gauge |
总的内存 | |
node_memory_MemFree_bytes |
Gauge |
空闲内存 | |
node_memory_Cached_bytes |
Gauge |
Cache 内存 | |
node_memory_Buffers_bytes |
Gauge |
Buffers 内存 |
(node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Cached_bytes - node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 |
| 指标名称 | 类型 | 说明 | 示例 |
|---|---|---|---|
node_network_receive_bytes_total |
Counter |
网卡接收的流量 | |
node_network_transmit_bytes_total |
Counter |
网卡发送的流量 |
irate(node_network_receive_bytes_total{device!~"cni0|docker.*|flannel.*|veth.*|virbr.*|lo",kubernetes_io_hostname=~"$node"}[$prometheusTimeInterval]) |
在 Project/App 的 models.py 文件中创建 model,当 model 定义完成,Django 会自动生产一个后台管理接口,允许认证用户添加、更改和删除对象,只需在管理站点上注册模型即可 [1]
在 Project/App 的 models.py 文件中创建 model
from django.db import models |
对修改后的 model 进行 migrate,以使在数据库中变更更改。
python manage.py makemigrations |
在 Project/App 的 admin.py 文件中注册 model
from django.contrib import admin |
更多有关 admin 配置方法,请参考 Django admin 配置